Rating Reviews for the API
Tuesday, 01 March 2022
To make SEPA's Hydrometric data as useful as possible for API users, we dedicated significant time and focus during 2021 to rectifying issues with the derived flow (Q) datasets. Whilst the biggest issue - which we focus on here - was discrepancies between the 15-minute data (Q.15m.Cmd) and the aggregated data (e.g. AMAX, POT), we also cleansed some other data anomalies.
How did data discrepancies come about?
Until the turn of the century, the primary dataset maintained by SEPA was mean daily flow (MDF, Q/HDay.Mean), which is a primary water resource management characteristic. Typically, historical ratings did not include well-defined flood segments; these are notoriously difficult to characterise, as there are generally limited, or no, observations in the relatively infrequent - and often dangerous to gauge - flood flows. Instead, they were extrapolated from the low-to-middle range stage-flow relationship, resulting in upper trajectories that often varied significantly between successive ratings, making them less reliable for flood estimation.
The progressive introduction of 15-minute stage (SG/15m.Cmd) and flow (Q/15m.Cmd) datasets between 1970 and 1990 created a new challenge: the higher resolution resulted in a calculation of flow during flood peaks, where previously these were obscured by the daily averaging. However, 15-minute flow typically derives from the rating used for Mean Daily Flow calculation with no specific flood calibration. In recent years, our ability to deliver more reliable high-resolution high-flow data has improved with the availability of advanced rating-creation software tools and a range of new gauging equipment with which to capture high-flow gaugings safely.
During the 1970’s the Institute of Hydrology started a project, working with the UK measuring authorities, to create high-flow ratings for flood datasets to support newly-developed flood estimation methods. This work resulted, in 2003, in a website (Hi-Flows UK) and a CD-ROM, to accompany flood estimation methods using WIN-FAP. Ownership of the flood datasets transferred to the National River Flow Archive in 2015, and the flood dataset was renamed to 'Peak Flows'. A key point is that development of high-flow ratings used distinct ratings for the upper (flood-flow) segments and that these were separate from those that generate the 15-minute flow and MDF archive held by SEPA.
These differences between 15-minute flow and certain aggregated flow statistics (where these were derived from the high-flow rating) mean that there may not be a unique flow value attributed to a flood peak. This is particularly problematic when 15-minute flow is used for event-based calibration and a different annual maximum flow (AMAX) is used for design flow estimates.
Solution
Over the past decade, we employed temporary-fixes to rectify the data discrepancies, rather than addressing the underlying problem wholesale. In preparation for release of the API, SEPA's hydrology staff have performed a rating 'unification' process for most of our stations. Some of the pre-digital data (usually pre-1990) are yet to be addressed as these present other significant issues that require cleansing and detailed quality control.
SEPA's applied solution has been to reassess all existing ratings to ensure that they are optimally calibrated for flood estimation, typically by inserting the recognised flood rating as an upper segment. This requires the high-flow ratings to be examined and, where necessary, modified; we then identify and make a suitable join between the segments or create a completely new rating for the site that covers the full stage range.
It was previously common practice to review ratings annually (often 1st January or October), even when there was no obvious change to a station's control. Where necessary, we have rationalised the number of ratings and updated the applied start dates to match the change in control.
Much of this work has only been possible with the benefit of hindsight: retrospection over a longer period allows a better understanding of the sites' flow variation in response to changing controls and under flood conditions than was possible when the original ratings were developed. The availability of new gaugings and, often, flood modelling has greatly informed this analysis, as has simply having more data to examine!
Philiphaugh
One extreme example is Philiphaugh, a long-standing station on the Yarrow Water in the Borders.
Prior to the recent 'unification', Philiphaugh flows were determined via a large number of ratings that were highly variable above stages of ~1.0m
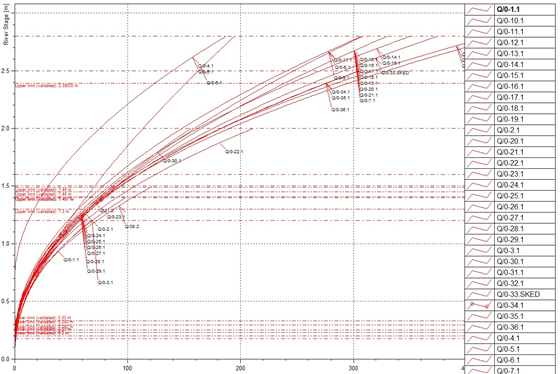
Post-unification, Philiphaugh flows are described by just five ratings, with only one major change, and otherwise similar upper segments (above 1.0m).
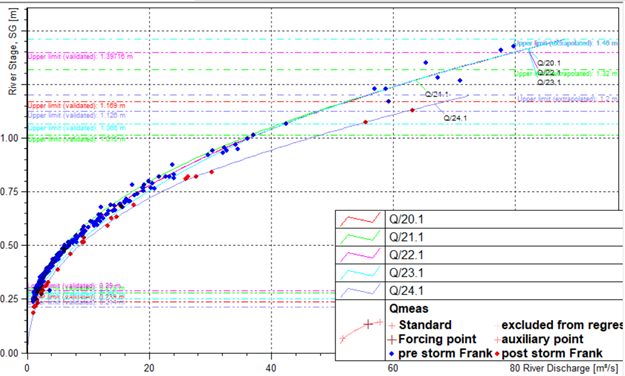
Future work
We will continue to refine stations that have yet to be reviewed; these include sites which are not suitable for inclusion in NRFA but are suitable for local flood estimates (for example, sites with short records, or in heavily modified catchments). We intend to add pre-digital data, which is a formidable task, but will significantly extend the records and enhance the value of our data.
How you can help
If you review or extend our data, or undertake rating reviews, and identify or correct any issues, please let us know via hydrometry-requests@sepa.org.uk. We’re interested to hear how you're using the data we hold, and we can publicise your work through case studies and news articles. Get in touch!